
Azureでは、各種Azureサービスの監視を行うために「Azure Monitor」が用意されています。このAzure Monitorは、ログの収集から通知までの一連の工程を総称した統合監視サービスを指します。今回は、このAzure Monitorができる事を見ていきたいと思います!
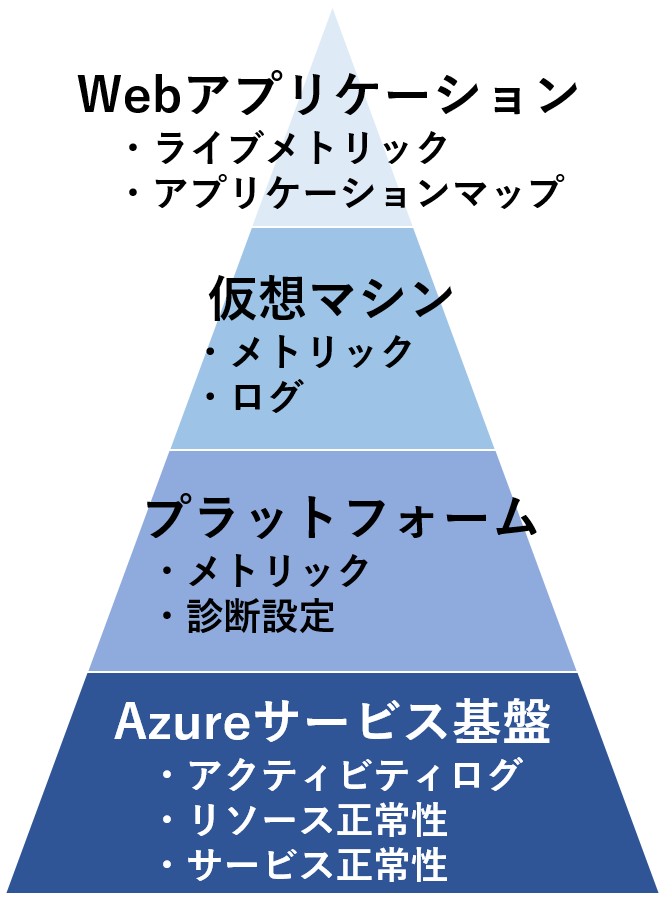
Azureリソースの監視を行う際の工程

ログ収集:各種リソースから、ログやメトリックを収集する工程
ログ保管:収集したログやメトリックをストレージに保管する工程
可視化/分析:グラフ化や特定の視点に立った分析などを行う工程
アラート:アクションを起こすためのトリガー(しきい値)を指定する工程
アクション:アラートを元に、メール通知、Function、LogicAppなどを実行する工程
Azureでは、これらのレイヤーからそれぞれに特化したログを収集します。
【ログ収集】
■サービス正常性
各種Azureサービスの稼働状態をリージョン単位で検知可能。大規模障害向け。
[サービスの問題/計画メンテナンス/正常性の勧告/セキュリティアドバイザリ]を検知。
デフォルトで有効化されており、90日間保存される。
※利用しているサービスしか検知されないので、すべてを選択しておいて問題無い。
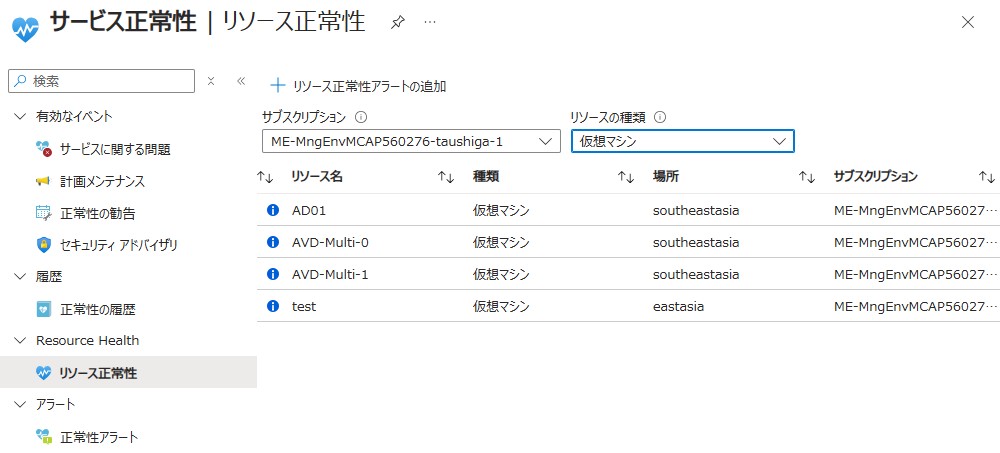
■リソース正常性
作成したリソースの状態変化を検知しアラートを通知する事が可能。ただし、すべてのリソースが対応しているわけではありません。各リソースごとに、確認する項目が決まっています。
デフォルトで有効化されており、30日間保存される。
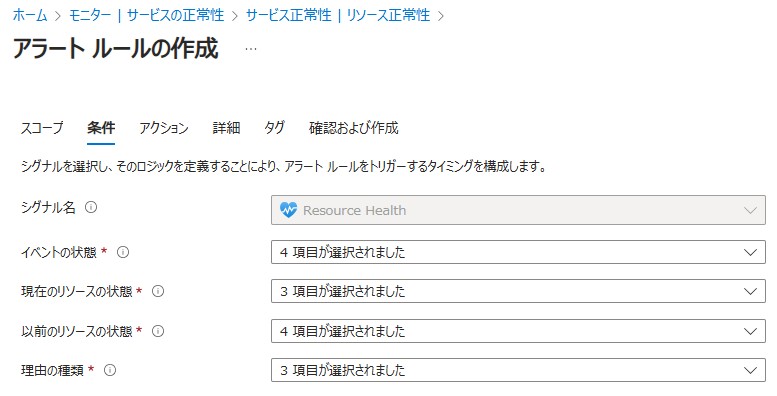
~アラートルールの作成方法~
[イベントの状態]
Active:異常状態
In Progress:状態変移中(異常状態)
Resolved:正常状態
Updated:状態変移完了(異常状態)
[現在のリソースの状態]
Available:リソースは[利用可能]です。
Degraded:リソースは[利用不可]です。
Unavailable:リソースの状態は[不明]です。
[以前のリソースの状態]
Available:リソースは[利用可能]です。
Degraded:リソースは[利用不可]です。
Unavailable:リソースの状態は[不明]です。
Unknown:リソースからの情報を10分以上受け取っていない状態
[理由の種類]
Platform Initiated:プラットフォーム起因
Unknown:起因不明
User Initiated:ユーザー起因
例:障害発生時にアラート通知する場合
以前:Available 現在:Degraded&Unavailable
例:障害復旧時にアラート通知する場合
以前:Degraded&Unavailable&Unknown 現在:Available
※特に要件が無ければ、全てを選択しておくとよい。後から不要な通知は削除できます。
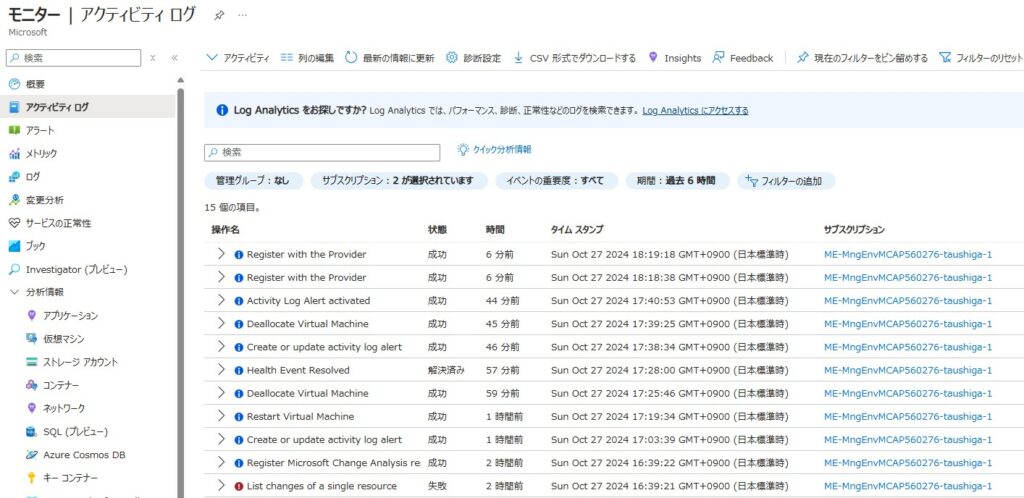
■アクティビティログ
サブスクリプションレベルでの操作ログ[だれが/いつ/何を実行したか]
ポータル上で閲覧したり、CSVでダウンロードが可能。
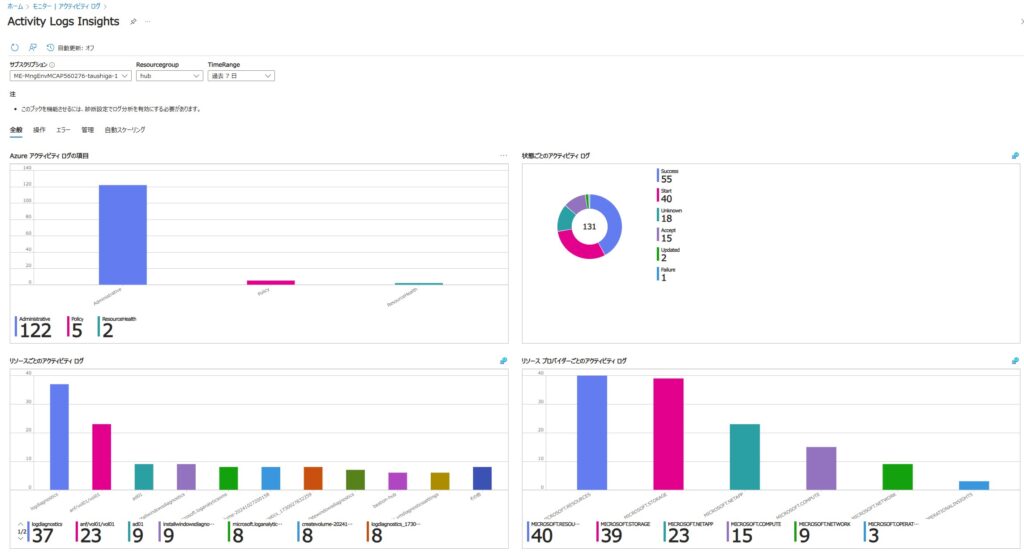
ワークブック[アクティビティ ログの分析情報]が用意されている。
デフォルトで有効化されており、90日間保存される。
※Log Analyticsワークスペースに送信しても、送信料/保管料(90日分)は無料となります。
■ログ設定
Administrative:ARMで実行される、作成/更新/削除の操作ログ
Security:Microsoft Defender for Cloudのアラートログ
ServiceHealth:サービス正常性ログ
Alert:アラートイベントのログ
Recommendation:Azure Advisorの推奨ログ
Policy:Azure Policyによって実行された操作ログ
Autoscale:オートスケールによって実行された操作ログ
ResourceHealth:リソース正常性ログ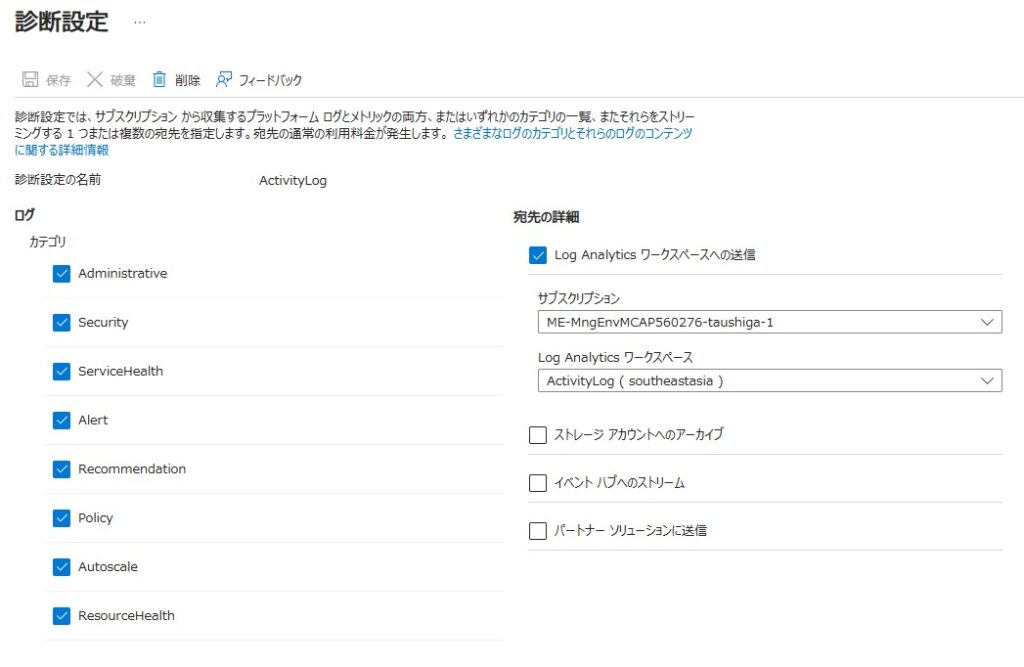
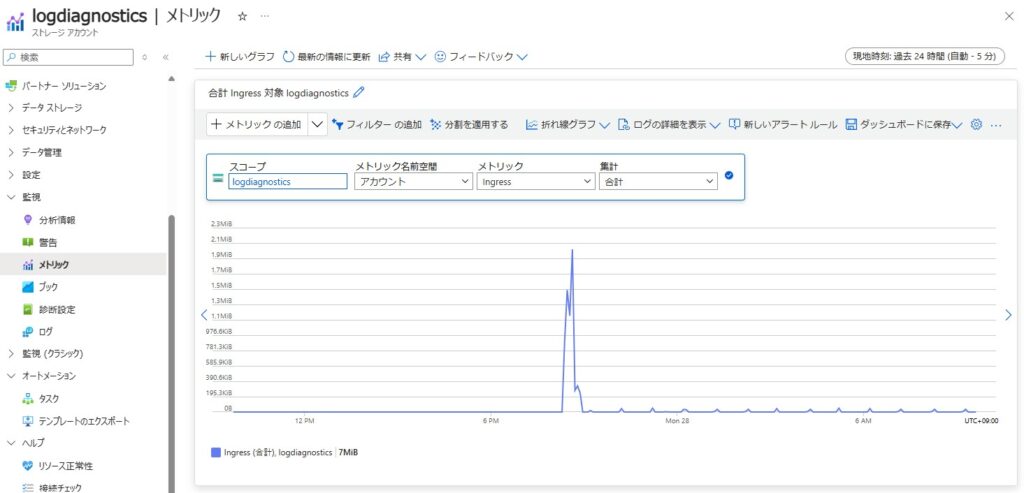
■プラットフォームメトリック
ホストサーバーから収集するメトリック情報。取得できるメトリックの内容はリソースにより異なる。ただし、全てのサービスが対応しているわけではありません。
デフォルトで有効化されており、93日間保存される。
■Azure Monitorリソースログ(診断設定)
Azureにある各種リソースから出力されるログ。取得できるログの内容はリソースにより異なる。ただし、全てのサービスが対応しているわけではありません。ログ保管が可能。

※メトリックとログの違いについて
メトリック:リアルタイムに問題を検知するための数値情報。定期的に収集。
ログ:原因調査/分析に利用するためのテキストや数値情報。イベント発生時に収集
■仮想マシン メトリック&ログ
①プラットフォームメトリック:ホストサーバー上から収集するメトリック情報。
デフォルトで有効化されており、93日間保存される。Azure Monitor Agentは不要
ディスク使用率などのホスト側から確認できない情報は取れません。
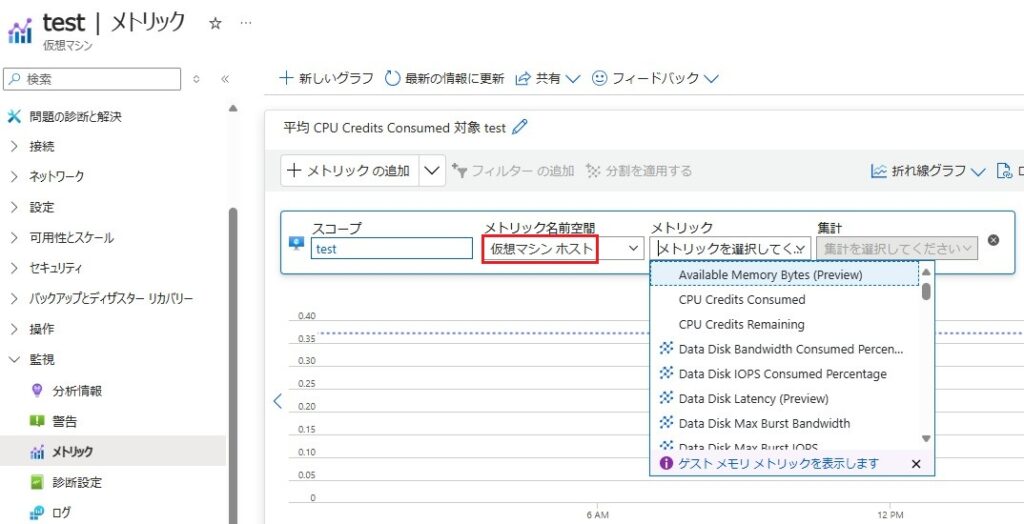
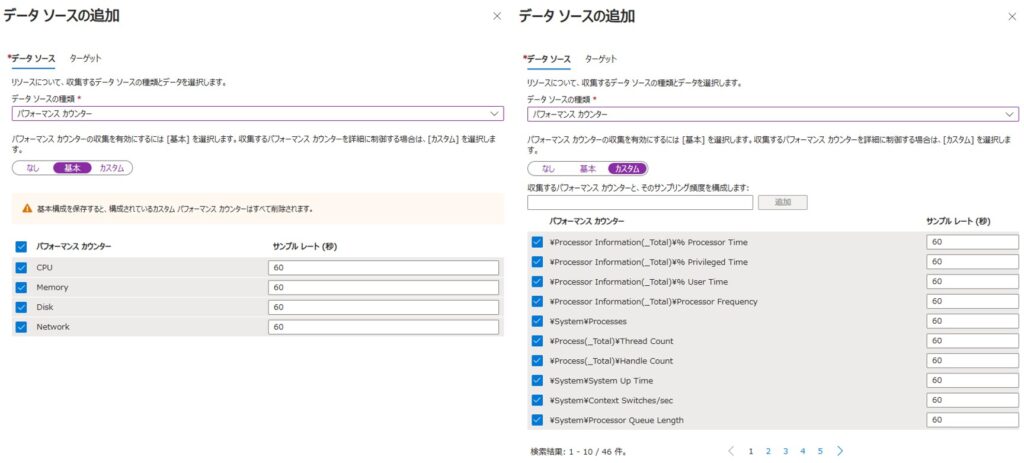
②仮想マシン(診断設定):イベントログ、パフォーマンスカウンターなどを”ストレージアカウント”に保存。ストレージアカウントなので、ログ検索アラートは利用できません。
Azure Monitor Agent (AMA)の”データ収集ルール”のような設定を下記画面にて行う。
Azure仮想マシンのみで利用できます。Azure Diagnostics Agentが必要
※2026年3月31日に廃止となります。
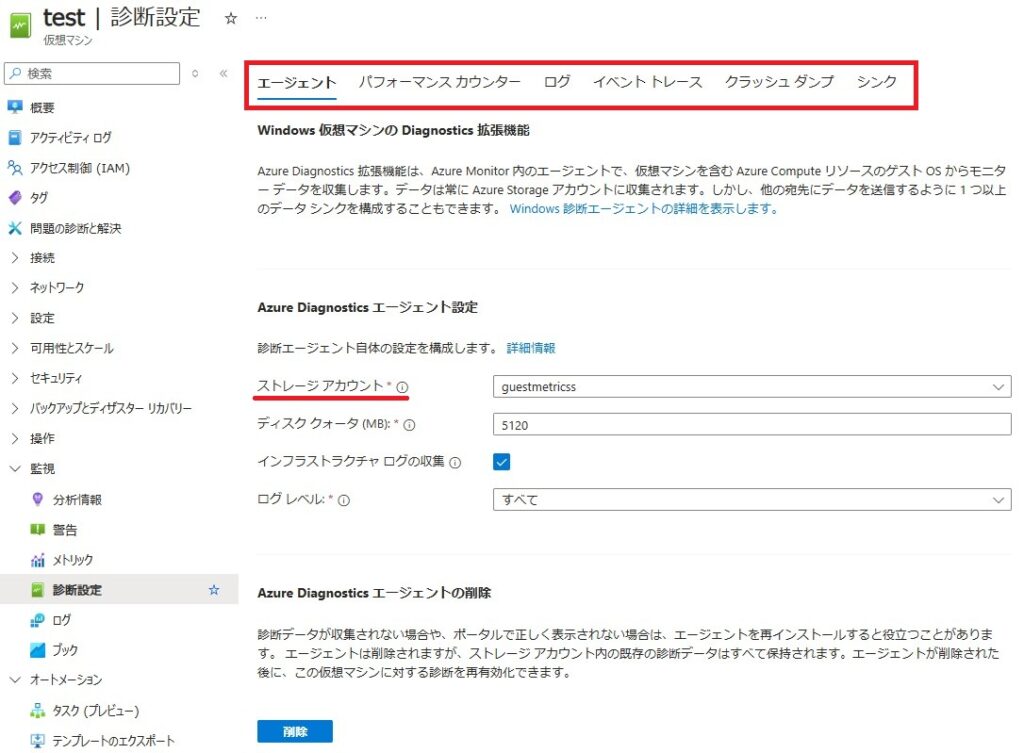
収集したパフォーマンスカウンターは、メトリック[ゲスト(クラシック)]で確認できます。
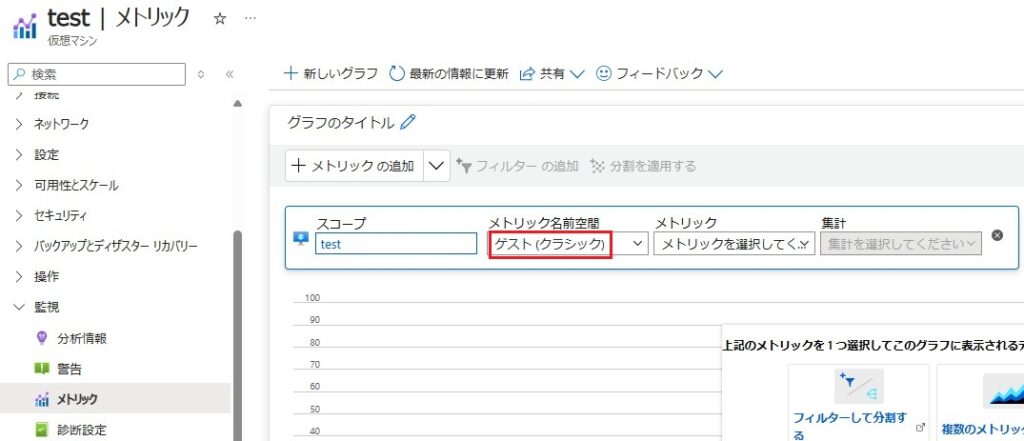
③仮想マシン(分析情報):仮想マシン内で収集したメトリック情報のみをLog Analyticsワークスペースに保存する。ワークブックがあり、ポータル上で可視化が可能。Azure Monitor Agentが必要
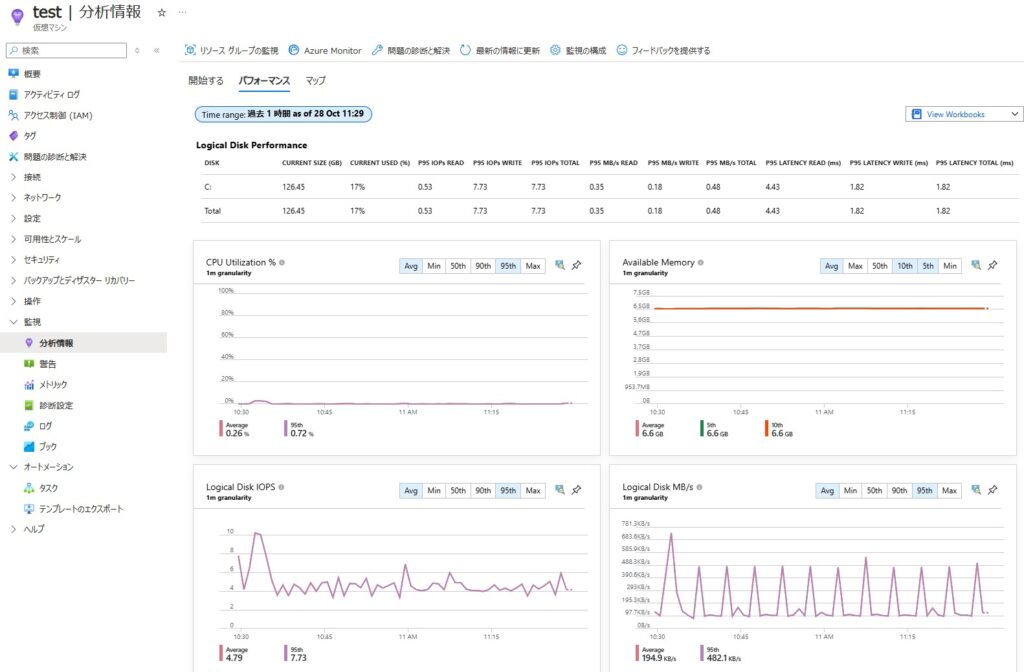
※[データ収集ルール]が自動作成され、パフォーマンスカウンター(カスタム) “\VmInsights\DetailedMetrics”のみが設定されている。
④Azure Monitor Agent (AMA) :各仮想マシンにインストールする事で、下記ログをLog Analyticsワークスペースに保存する事ができます。Azure以外の仮想マシンも対象にできる。
[Azure Monitor Agent (AMA) で収集可能なログ]
・パフォーマンスカウンター [Windows/Linux]
・Windowsイベントログ [Windows]
・Syslog [Linux]
・テキストログ [Windows/Linux]
・JSONログ [Windows/Linux]
・Windows IISログ [Windows]
・Windows ファイアウォールログ [Windows]
※これらのログは、[データ収集ルール]にて取捨選択が可能
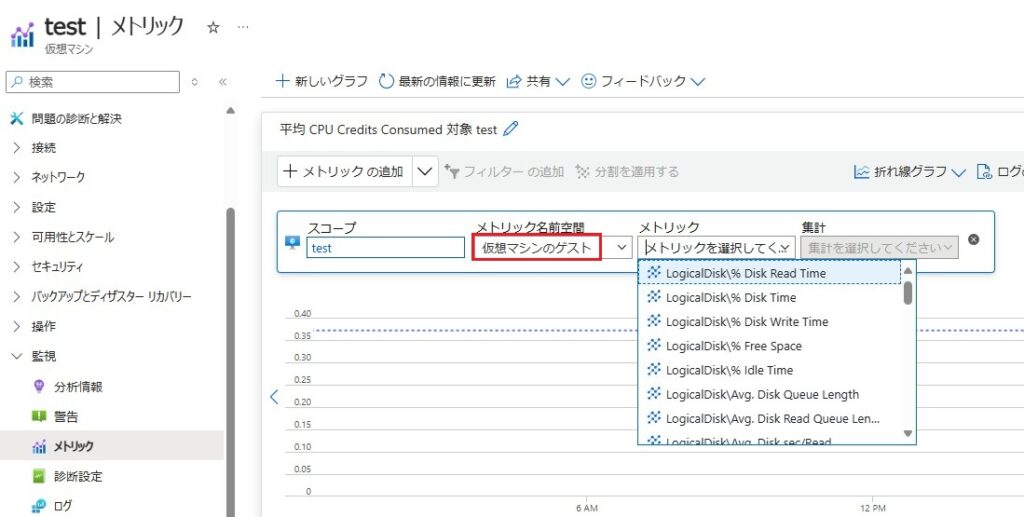
パフォーマンスカウンターは、メトリック[仮想マシンのゲスト]で確認できます。
OSから収集しているので、プラットフォームメトリックより詳細な情報が収集可能です。
【死活監視について】
Azure Monitor Agentから[Heartbeat]をLog Analyticsワークスペースに対して、1分間隔で送信します。このHeartbeatの受信状況を確認する事で死活監視が行えます。
ただし、HeartbeatがLog Analyticsワークスペースに届くには、20~180秒ほどのタイムラグがあります。また、Azure側の負荷や障害などにより、Heartbeatの送信に遅延が生じる場合があります。より精度を高めるためには、死活監視の冗長化をお勧め致します。
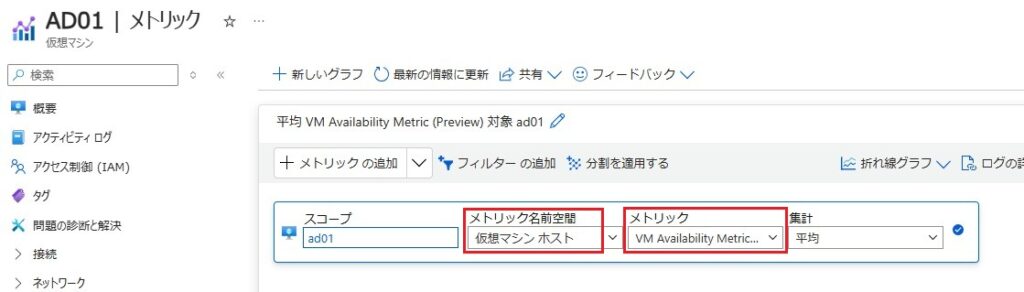
VM可用性メトリック(プレビュー):プラットフォームメトリック[VM Availability Metric]を利用してVMの死活監視を行う。Log Analyticsワークスペースを利用しないので、Heartbeatに比べて精度が高い。ただし”割り当て解除”の判断はできません。Azure Monitor Agent不要
おまけ:Entra IDでのログ取得について
サインインログ:EntraIDへのサインイン履歴。デフォルトで7日間保存。P1,P2で30日間保存
サインインユーザー、利用したクライアントアプリ、ターゲットリソースが収集されます。
【ログ保管】
■Log Analyticsワークスペース
Analyticsログ:各種ログを複数の分析テーブルに保存する事でKusto(KQL)でのログ検索を可能にしたデータストア。過去2年分のログ検索が可能。ログ検索アラートが利用可能。最大12年間保存可能。
Basicログ:Analyticsログに比べ、価格は約1/5。過去30日分のログ検索が可能。主にメトリック テーブルが利用可能。
※テーブルプランの切り替えは、即時反映され、週1回変更が可能です。
■ストレージアカウント
保存容量に応じた課金。GRS利用によるリージョン冗長構成が容易。保存期間に制限無し
■イベントハブ
ログデータをリアルタイムに加工/変換する事が可能。自前のデータ処理システムに送信可能
■パートナーソリューション
管理機能に特化したサードパーティーソリューションの利用が可能。使い慣れたサービスを利用できます。
【可視化/分析】
■ダッシュボードタイル形式で、メトリック、グラフ、リスト表などを自由に配置する事ができる。作成したダッシュボードは共有する事も可能。
・メトリックエクスプローラー:ポータル上に表示されるテレメトリ情報
・VM Insights(分析情報):Log Analyticsワークスペースに収集されたメトリック情報をポータル上に表示
・ワークブック:既定で用意されている可視化用テンプレート。オリジナルテンプレートを作成する事も可能。Log Analyticsワークスペースへの保管が必要。
・Application Insights:Webアプリケーション専用メトリックを提供
(セッション数、エラー率、応答速度、パフォーマンスなど)
※Log Analyticsワークスペースに送信しても、送信料/保管料(90日分)は無料となります。
・AppAvailabilityResults
・AppBrowserTimings
・AppDependencies
・AppExceptions
・AppEvents
・AppMetrics
・AppPageViews
・AppPerformanceCounters
・AppRequests
・AppSystemEvents
・AppTraces
【アラートルール】
【アラートの種類】
■アクティビティログアラート:アクティビティログ、リソース/サービス正常性が対象
■メトリックアラート:プラットフォームメトリック、カスタムメトリックが対象
※デフォルト設定は、ステートフル
■ログ検索アラート:事前に定義した、Log Analyticsワークスペース Kustoクエリでの検知が対象 ※デフォルト設定は、ステートレス
■スマート検出アラート:Application Insights でのパフォーマンス、障害検知が対象
■プロメテウスアラート:Prometheusメトリックのアラートが対象
【ステートレスとステートフルについて】
・ステートレス:アラート解決の有無に関わらず、アラート条件を満たす度に発報されます。
・ステートフル:アラート条件を満たした時に発報されますが、そのアラートが解決されるまでは再度条件を満たしてもアラートは発報されません。
アラート履歴は、30日間保存されます。
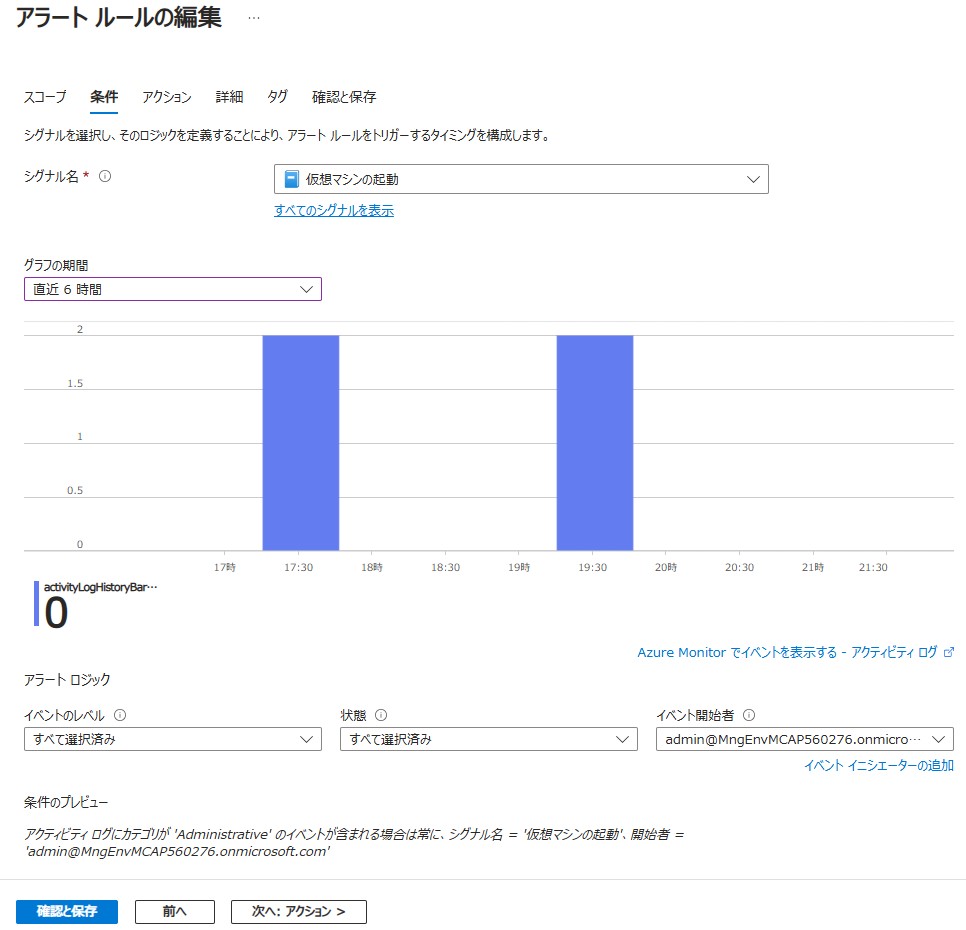
アクティビティログ アラート
シグナル名:サブスクリプション内での特定の操作を指定 ※仮想マシンの起動/削除など
イベントのレベル:[重大 / エラー / 警告 / 情報 / 詳細] ※重要度を自身で指定
状態:[開始 / 成功 / 失敗]
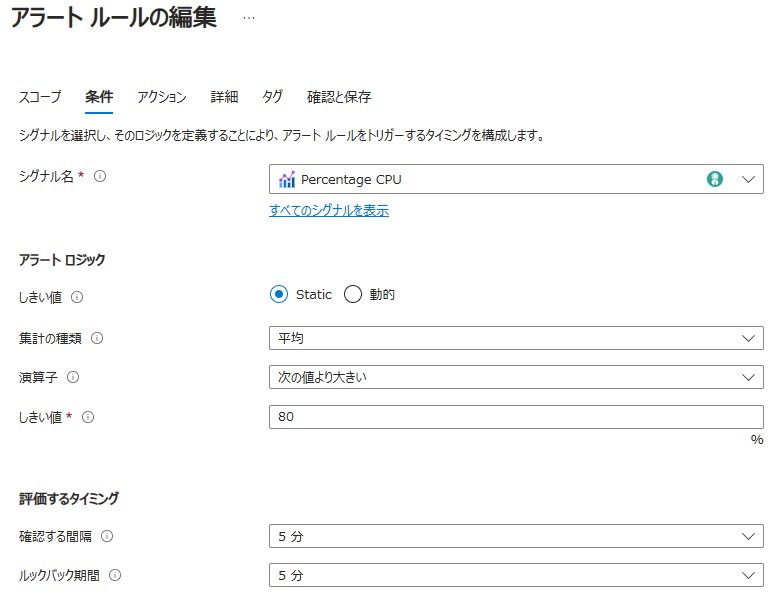
メトリック アラート
シグナル名:メトリックを指定
しきい値:[Static / 動的] ※動的=機械学習による自動設定
集計の種類:[最小 / 平均 / 最大]
※動的の場合、”最大”を選択しない事をお勧めします。
演算子:[次の値より大きい / 次の値以上 / 次の値より小さい / 次の値以下]
※動的の場合、アプリの使用状況を除き”次の値より大きい”を選択
単位:[カウント / カウント(B) / カウント(K) / カウント(M)]
しきい値:数値を入力 ※Staticの場合
しきい値の感度:[大 / 中 / 小] ※動的の場合、”大”を選択しない事をお勧めします。
確認する間隔:アラートの評価を実行する間隔
ルックバック期間:評価対象となる期間
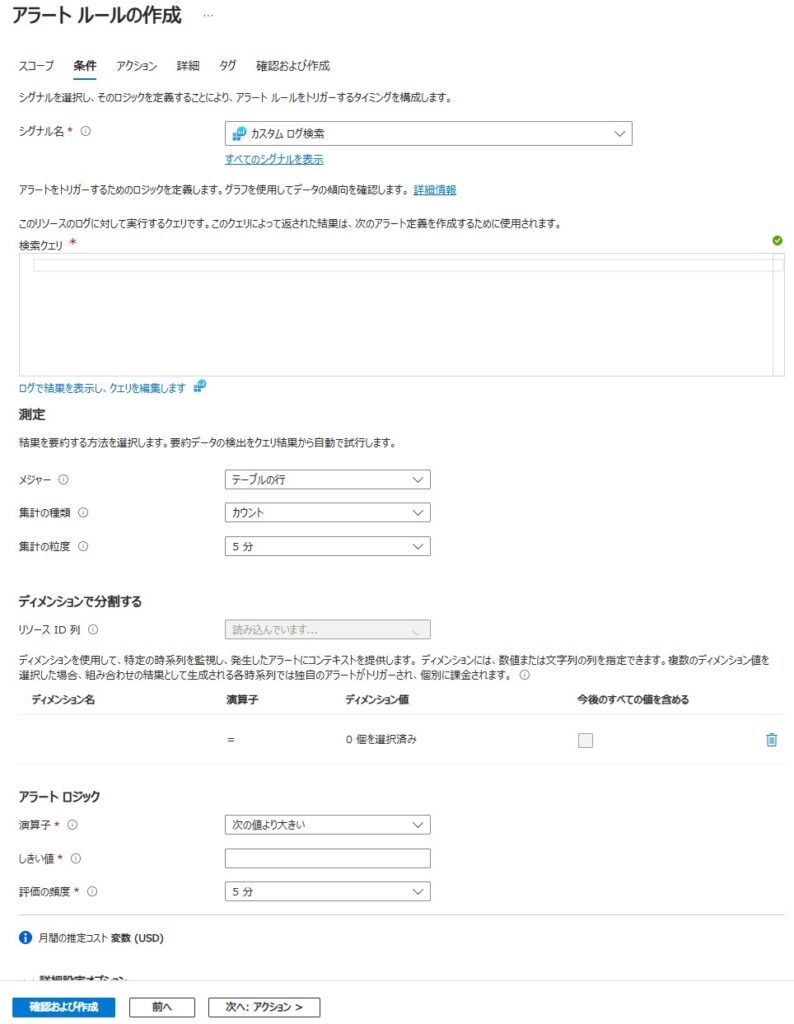
ログ検索 アラート
シグナル名:カスタムログ検索
検索クエリ:テーブルを指定して、Kustoクエリにて自由に検索が可能
メジャー行:テーブルの行(変更不可)
集計の種類:カウント(変更不可)
集計の粒度:評価対象となる期間
演算子:[次の値より大きい / 次の値以上 / 次の値より小さい / 次の値以下 / 等しい]
しきい値:※数値を入力
評価の頻度:検索クエリを実行する間隔
【誤報が多い場合】
・アラートの評価期間を見直す。”集計の粒度”や”評価の頻度”をより長く設定する
・アラートのしきい値を見直す。動的の場合”小”を選択
【アクション グループ】
アラートルールでの検知をトリガーにし、指定した[通知][アクション]を行う事ができます。
※[アクション処理ルール]を利用すると、アクショングループを有効化する日時を指定可能
・通知:電子メール、SMS、プッシュ通知、音声通知を行う
・アクション:Runbook、Function、ITSM、Webhook、Eventhub、LogicAppの実行
アラートルールで検知した内容をメール送信
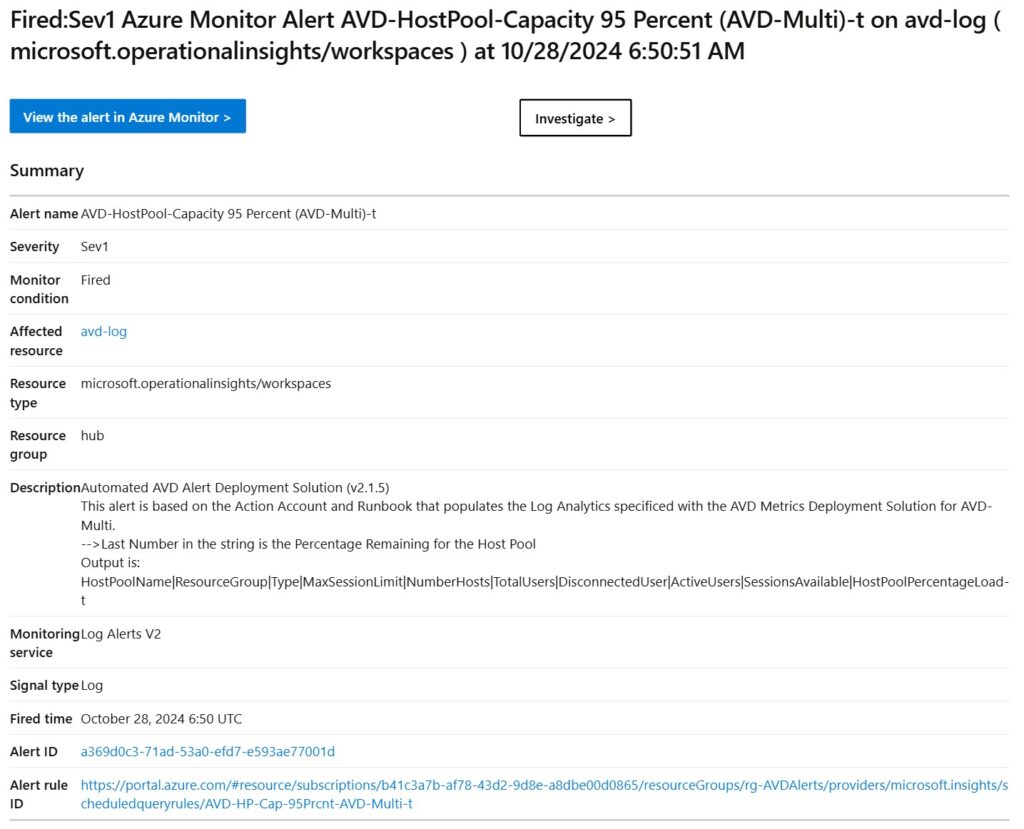
LogicAppを利用する事でTeamsに通知する事もできます。
【コスト】
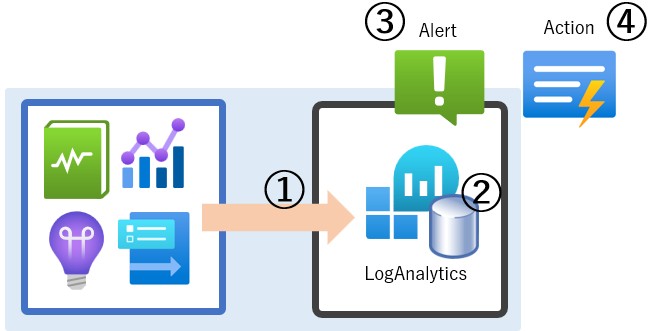
①Log Analyticsワークスペースにデータを取り込んだデータ量
②Log Analyticsワークスペースに保存したデータ容量
③メトリックアラートの場合[作成したアラートの数] / ログ検索アラートの場合[評価の頻度]
④アクショングループを実行した回数
※アクティビティログ アラート、サービス正常性アラート、リソース正常性アラートは無料
~節約のために~
・パフォーマンス、イベントログの収集頻度を減らす。
・パフォーマンス、イベントログの収集項目を減らす。
・Log Analyticsワークスペースに取り込むデータの日次上限を設定する。
・Log Analyticsワークスペースの保存期間を短くする。
・ストレージアカウント(Blob)の利用を検討する。
・仮想マシン(分析情報)の利用を再検討する。
・ログ検索アラートを使用する場合は、ログ検索アラートの頻度を最小限に抑えます。
・メトリック アラートを使用する場合は、監視対象のリソースの数を最小限に抑えます。



